读论文:SpecInfer
本文最后更新于 2025年3月10日
ASPLOS 2024
标题:SpecInfer: Accelerating Large Language Model Serving with Tree-based Speculative Inference and Verification
作者:Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, Zhihao Jia
Affiliation: Carnegie Mellon University; Tsinghua University; Shanghai Jiao Tong University; Peking University; University of California, San Diego
Existing problem
模型的选择是一种 tradeoff
- 大模型性能更好,但是推理成本高
- 小模型性能差,但是推理成本低
那有没有鱼与熊掌兼得的办法呢?
Sepculative Inference
LLM推理的瓶颈内存/显存访问,每生成一个token就要读取所有权重
Sepculative Inference 的做法是让一个小模型一次生成多个toekn,然后再让 LLM 去验证输出
(相当于做了batch,减少访存)
比如说小模型生成“我要吃麦当劳”
大模型需要验证的就是
- 我
- 我要
- 我要吃
- 我要吃麦
- 我要吃麦当
这些序列的下一个token是不是和小模型输出相同
这种加速方法有效的原因是,小模型的时间可以忽略不计,大模型最后至少能生成一个token,相当于时间基本不变
实际的加速比会受限于以下三个因素
- 小模型的速度
- 两者输出的对齐程度
- 大模型验证是否高效
Tree-based Speculative Inference and Verification
Specinfer 希望解决后两个问题
一个观察是,同时保留小模型输出的多个高概率的token,成功率会大大提高
- Learning-based Speculator: 使用了多个 SSM(Small Speculative Model),并使用了类似集成学习的方法使多个 SSM 的输出尽可能覆盖 LLM 的输出 每次只训练一个 SSM,当 SSM 训练完成后,将训练集中这个SSM 的输出与 LLM 输出一致的那些训练数据删去,并用剩下的训练集继续训练下一个 SSM。这样,多个 SSM 的输出可以尽可能地覆盖到 LLM 可能的输出。
- Tree-based Verifier
现在有四个序列,做四次验证是非常低效的
本文首次提出了Tree Attention,想法非常简单,使用与树的形状相匹配的mask
这样就可以一次性做完四条序列的验证
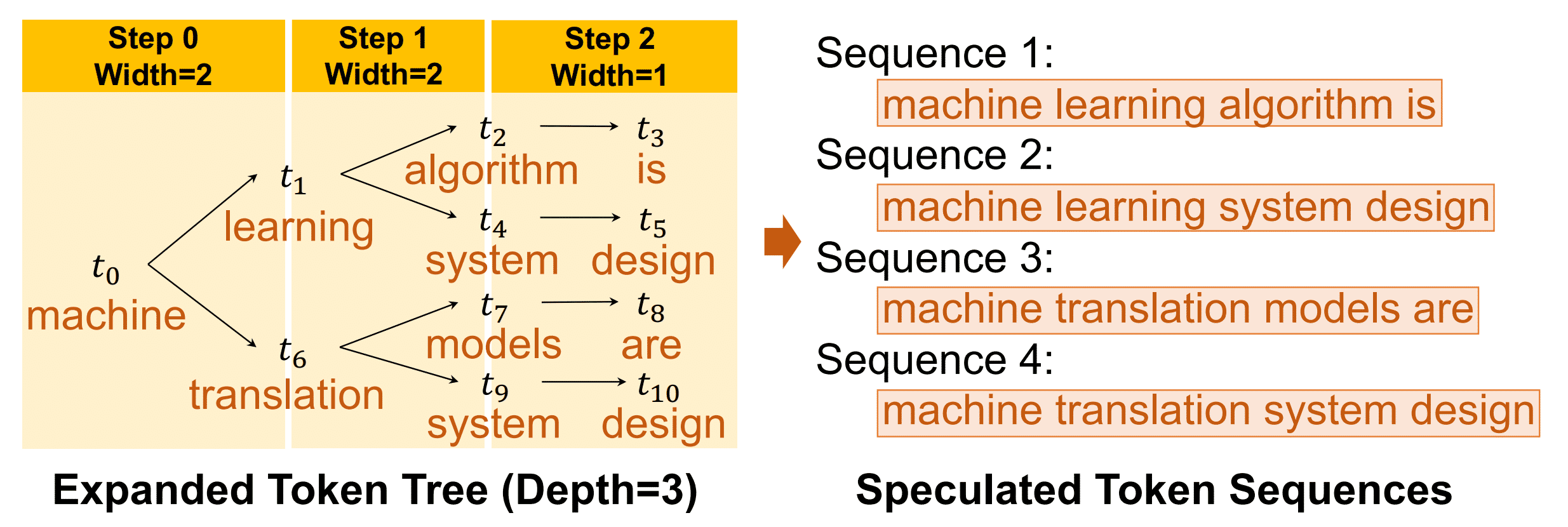

Overview
Tree attention基本是后续Speculative Decoding 的标配了

相关链接
https://huggingface.co/blog/zh/assisted-generation
https://drive.google.com/file/d/138bR9IQPEdSKBBETGKM-Ktt7BkAlSkp7/view
https://speculative-decoding.github.io/